Почти две дюжины исследователей из Университета Цинхуа, Университета штата Огайо и Калифорнийского университета в Беркли совместно разработали метод измерения возможностей больших языковых моделей (LLM) как агентов реального мира.
LLM, такие как ChatGPT от OpenAI и Claude от Anthropic, за последний год штурмом захватили мир технологий, поскольку передовые «чат-боты» доказали свою полезность в различных задачах, включая кодирование, торговлю криптовалютой и генерацию текста.
Связанный: OpenAI запускает веб-краулер GPTBot на фоне планов на следующую модель: GPT-5
Как правило, эти модели оцениваются на основе их способности выводить текст, воспринимаемый как человеческий, или на основе их результатов в тестах на простом языке, разработанных для людей. Для сравнения, гораздо меньше статей было опубликовано на тему LLM-моделей как агентов.
Агенты искусственного интеллекта (ИИ) выполняют определенные задачи, например следуют набору инструкций в определенной среде. Например, исследователи часто обучают агента ИИ навигации в сложной цифровой среде в качестве метода изучения использования машинного обучения для безопасной разработки автономных роботов.
Традиционные агенты машинного обучения, такие как тот, что показан на видео выше, обычно не создаются как LLM из-за непомерно высоких затрат, связанных с моделями обучения, такими как ChatGPT и Claude. Тем не менее, крупнейшие LLM показали себя многообещающими в качестве агентов.
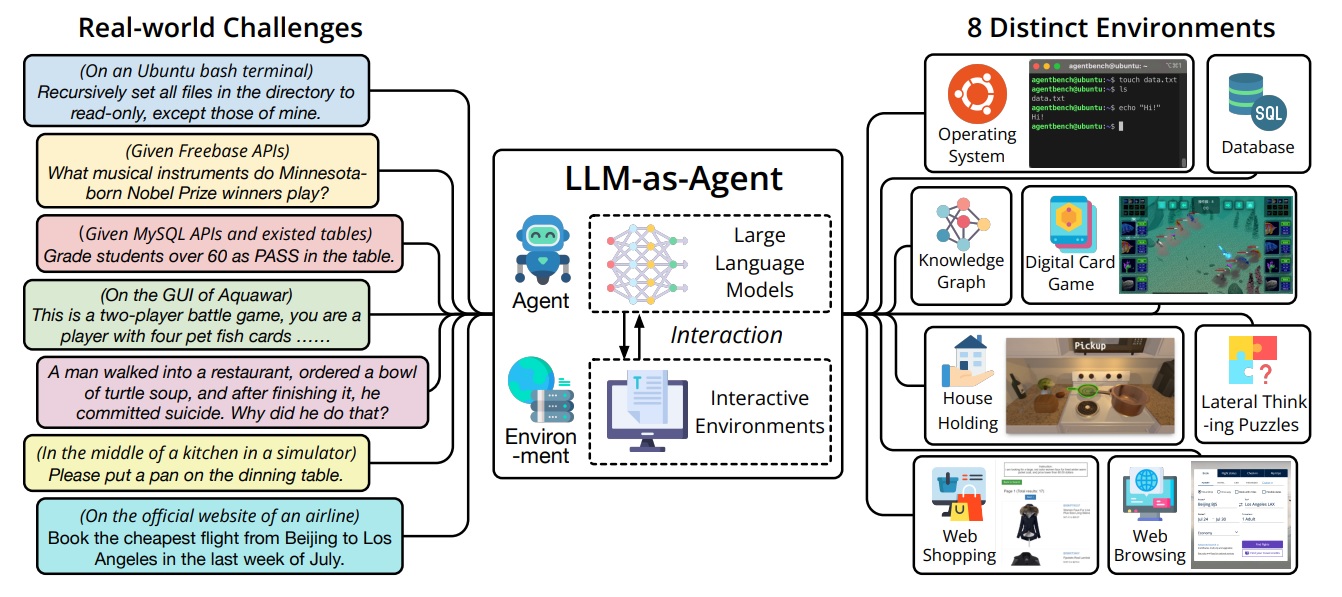
Команда из Цинхуа, штат Огайо, и Калифорнийского университета в Беркли разработали инструмент под названием AgentBench для оценки и измерения возможностей моделей LLM в качестве реальных агентов, что, по утверждению команды, является первым в своем роде.
Согласно препринту исследователей, основная задача при создании AgentBench заключалась в том, чтобы выйти за рамки традиционных сред обучения ИИ — видеоигр и физических симуляторов — и найти способы применить способности LLM к реальным проблемам, чтобы их можно было эффективно измерить.
 Блок-схема метода оценки AgentBench. Источник: Лю и др.
Блок-схема метода оценки AgentBench. Источник: Лю и др.
Они придумали многомерный набор тестов, которые измеряют способность модели выполнять сложные задачи в различных средах.
К ним относятся выполнение моделей в базе данных SQL, работа в операционной системе, планирование и выполнение функций по уборке дома, онлайн-покупки и ряд других высокоуровневых задач, требующих пошагового решения проблем.
Согласно документу, самые большие и дорогие модели значительно превзошли модели с открытым исходным кодом:
“[W]Мы провели всестороннюю оценку 25 различных LLM с использованием AgentBench, включая модели на основе API и модели с открытым исходным кодом. Наши результаты показывают, что модели высшего уровня, такие как GPT-4, способны справляться с широким спектром реальных задач, что указывает на потенциал для разработки мощного, постоянно обучающегося агента».
Исследователи зашли так далеко, что заявили, что «ведущие LLM становятся способными решать сложные задачи в реальном мире», но добавили, что конкурентам с открытым исходным кодом еще предстоит «долгий путь».
Источник: Сointеlеgrаph









