Грядущая модель искусственного интеллекта OpenAI обеспечивает меньший прирост производительности, чем ее предшественники, сообщили The Information источники, знакомые с этим вопросом.
Тестирование сотрудников показало, что компания Orion достигла уровня GPT-4 после завершения лишь 20% обучения, сообщает The Information.
Повышение качества от GPT-4 до текущей версии GPT-5 кажется меньшим, чем от GPT-3 до GPT-4.
«Некоторые исследователи в компании считают, что Orion не намного лучше своего предшественника в решении определенных задач, по мнению сотрудников (OpenAI)», — сообщает The Information. «По словам сотрудника OpenAI, Orion лучше справляется с языковыми задачами, но может не превзойти предыдущие модели в таких задачах, как кодирование».
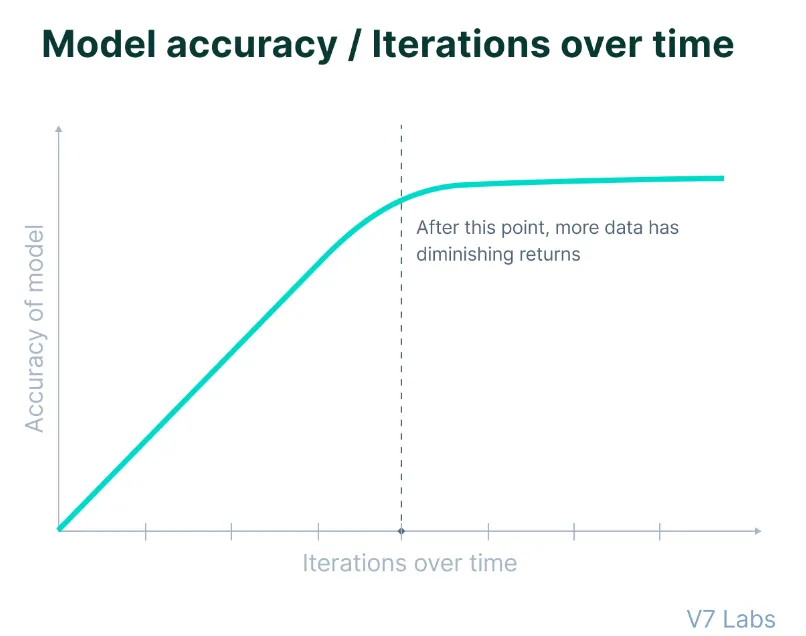
Хотя приближение Ориона к GPT-4 при 20% обучения может показаться некоторым впечатляющим, важно отметить, что ранние этапы обучения ИИ обычно дают наиболее существенные улучшения, а последующие этапы приносят меньшие результаты.
Таким образом, оставшиеся 80% времени обучения вряд ли принесут такой же масштаб прогресса, как при скачках предыдущих поколений, говорят источники.
 Изображение: Лаборатория V7
Изображение: Лаборатория V7
Ограничения возникают в критический момент для OpenAI после недавнего раунда финансирования в размере 6,6 миллиардов долларов.
Сейчас компания сталкивается с повышенными ожиданиями инвесторов, одновременно борясь с техническими ограничениями, которые бросают вызов традиционным подходам к масштабированию в разработке ИИ. Если эти ранние версии не оправдают ожиданий, предстоящие усилия компании по сбору средств могут не быть встречены с таким ажиотажем, как раньше, и это может стать проблемой для потенциально коммерческой компании, чего Сэм Альтман, похоже, и хочет для OpenAI. .
Неутешительные результаты указывают на фундаментальную проблему, стоящую перед всей индустрией искусственного интеллекта: уменьшение количества высококачественных обучающих данных и необходимость оставаться актуальными в такой конкурентной области, как генеративный искусственный интеллект.
Исследование, опубликованное в июне, прогнозирует, что компании, занимающиеся искусственным интеллектом, исчерпают доступные общедоступные текстовые данные, созданные человеком, в период с 2026 по 2032 год, что станет критическим переломным моментом для традиционных подходов к развитию.
«Наши результаты показывают, что текущие тенденции развития LLM не могут быть поддержаны только за счет традиционного масштабирования данных», — говорится в исследовательском документе, подчеркивая необходимость альтернативных подходов к совершенствованию моделей, включая генерацию синтетических данных, передачу обучения из областей, богатых данными, и использование непубличных данных.
Историческая стратегия обучения языковых моделей на общедоступном тексте с веб-сайтов, книг и других источников достигла точки убывающей отдачи, поскольку разработчики «в значительной степени выжали из этого типа данных столько, сколько могли», согласно The Information. .
Как OpenAI решает эту проблему: рассуждения против языковых моделей
Чтобы решить эти проблемы, OpenAI фундаментально реструктурирует свой подход к разработке ИИ.
«В ответ на недавнюю проблему, связанную с законами масштабирования на основе обучения, вызванную замедлением совершенствования GPT, отрасль, похоже, переключает свои усилия на улучшение моделей после их первоначального обучения, что потенциально приводит к другому типу закона масштабирования», — сообщает The Information.
Чтобы достичь такого состояния постоянного совершенствования, OpenAI разделяет разработку моделей на два отдельных направления:
Серия O (которая, судя по всему, имеет кодовое название Strawberry), ориентированная на возможности рассуждения, представляет собой новое направление в архитектуре моделей. Эти модели работают со значительно более высокой вычислительной интенсивностью и специально предназначены для решения сложных задач.
Вычислительные требования значительны: по предварительным оценкам, эксплуатационные затраты в шесть раз превышают текущие модели. Однако расширенные возможности рассуждения могут оправдать увеличение расходов на конкретные приложения, требующие расширенной аналитической обработки.
Эта модель, если она такая же, как Strawberry, также призвана генерировать достаточно синтетических данных для постоянного повышения качества LLM OpenAI.
Параллельно модели Orion или серия GPT (учитывая, что OpenAI является торговой маркой GPT-5) продолжают развиваться, уделяя особое внимание общим задачам обработки языка и коммуникации. Эти модели поддерживают более эффективные вычислительные требования, одновременно используя более широкую базу знаний для задач письма и аргументации.
Технический директор OpenAI Кевин Вейл также подтвердил это во время AMA и сказал, что рассчитывает объединить обе разработки в какой-то момент в будущем.
«Это не либо, либо и то, и другое», — ответил он, когда его спросили, будет ли OpenAI фокусироваться на масштабировании LLM с большим количеством данных или использовать другой подход, сосредоточив внимание на меньших, но более быстрых моделях, «лучших базовых моделях плюс больше вычислений по времени клубничного масштабирования/вывода. »
Обходной путь или окончательное решение?
Подход OpenAI к решению проблемы нехватки данных посредством генерации синтетических данных представляет собой сложные проблемы для отрасли. Исследователи компании разрабатывают сложные модели, предназначенные для генерации обучающих данных, однако это решение создает новые сложности в поддержании качества и надежности моделей.
Как ранее сообщал Decrypt, исследователи обнаружили, что обучение моделей на синтетических данных представляет собой палку о двух концах. Несмотря на то, что он предлагает потенциальное решение проблемы нехватки данных, он создает новые риски деградации модели и проблемы с надежностью, которые доказывают ухудшение после нескольких итераций обучения.
Другими словами, по мере того, как модели обучаются на контенте, созданном ИИ, они могут начать усиливать тонкие недостатки в своих результатах. Эти петли обратной связи могут закреплять и усиливать существующие предубеждения, создавая комплексный эффект, который становится все труднее обнаружить и исправить.
Команда OpenAI Foundations разрабатывает новые механизмы фильтрации для поддержания качества данных, внедряя различные методы проверки, чтобы различать высококачественный и потенциально проблемный синтетический контент. Команда также изучает гибридные подходы к обучению, которые стратегически объединяют контент, созданный человеком и искусственным интеллектом, чтобы максимизировать преимущества обоих источников и минимизировать их соответствующие недостатки.
Оптимизация после обучения также приобрела актуальность. Исследователи разрабатывают новые методы повышения производительности модели после начального этапа обучения, потенциально предлагая способ улучшить возможности, не полагаясь исключительно на расширение набора обучающих данных.
Тем не менее, GPT-5 все еще является зародышем законченной модели, и впереди ее ждут значительные разработки. Сэм Альтман, генеральный директор OpenAI, заявил, что система не будет готова к развертыванию в этом или следующем году. Этот расширенный график может оказаться полезным, поскольку позволит исследователям устранить текущие ограничения и потенциально открыть новые методы улучшения модели, что значительно улучшит GPT-5 перед его окончательным выпуском.
В целом интеллектуальный информационный бюллетень
Еженедельное путешествие по искусственному интеллекту, рассказанное Дженом, генеративной моделью искусственного интеллекта.








