Генеральный директор Anthropic Дарио Амодей говорит, что человечество приблизилось, чем ожидалось, к тому моменту, когда модели искусственного интеллекта будут такими же умными и способными, как люди.
Амодей также обеспокоен потенциальными последствиями появления ИИ человеческого уровня.
«Сильные вещи могут делать хорошие дела, а могут и плохие», — предупредил Амодей. «С большой силой приходит и большая ответственность».
Действительно, Амодей предполагает, что общий искусственный интеллект может превзойти человеческие возможности в течение следующих трех лет. Это преобразующий сдвиг в технологиях, который должен принести как беспрецедентные возможности, так и риски — независимо от того, готовы мы к этому или нет.
«Если вы просто посмотрите на скорость, с которой растут эти возможности, вы действительно думаете, что мы доберемся до этого к 2026 или 2027 году», — сказал Амодей интервьюеру Лексу Фридману. Это при условии, что не возникнет серьезных технических препятствий, сказал он.
Это, конечно, проблематично: ИИ может обратить зло и стать причиной потенциально катастрофических событий, сказал генеральный директор.
Он также выразил обеспокоенность по поводу давней «корреляции», как он ее сформулировал, между высоким человеческим интеллектом и нежеланием совершать вредные действия. Эта корреляция между мозгом и относительным альтруизмом исторически защищала человечество от разрушения.
«Если я сегодня посмотрю на людей, которые совершили в мире действительно плохие вещи, то пойму, что человечество было защищено тем фактом, что совпадение между действительно умными, хорошо образованными людьми и людьми, которые хотят делать действительно ужасные вещи, как правило, было небольшим», он сказал: «Меня беспокоит то, что, будучи гораздо более умным агентом, ИИ может разрушить эту корреляцию», — сказал он.
Он добавил: «Самый масштабный масштаб — это то, что я называю катастрофическим злоупотреблением в таких областях, как кибер, биология, радиология, ядерная энергия. Вещи, которые могут нанести вред или даже убить тысячи, даже миллионы людей», — сказал он.
Но по своей сути человеческое зло действует в обе стороны. Амодей утверждал, что, будучи новой формой интеллекта, модели ИИ могут не быть связаны теми же этическими и социальными ограничениями, которые управляют поведением человека, такими как тюремное заключение, социальное остракизм и казнь.
Он предположил, что несогласованным моделям ИИ может не хватать врожденного отвращения к причинению вреда, которое люди испытывают за годы общения, проявления сочувствия или разделения моральных ценностей. Для ИИ риска потери нет.
И есть другая сторона медали. Злоумышленники могут манипулировать системами ИИ или вводить их в заблуждение — тех, кто использует ИИ, чтобы разрушить корреляцию, упомянутую Амодеем.
Если злой человек воспользуется уязвимостями в обучающих данных, алгоритмах или даже в оперативном проектировании, модели ИИ могут совершать злонамеренные действия без ведома. Это варьируется от чего-то столь же глупого, как создание обнаженных изображений (в обход внутренних правил цензуры), до потенциально катастрофических действий (например, представьте себе взлом ИИ, который обрабатывает ядерные коды).
AGI, или общий искусственный интеллект, — это состояние, в котором ИИ достигает человеческой компетентности во всех областях, что делает его способным понимать мир, адаптироваться и совершенствоваться так же, как это делают люди. Следующий этап, ИСИ или искусственный сверхинтеллект, как правило, подразумевает машины, превосходящие человеческие возможности.
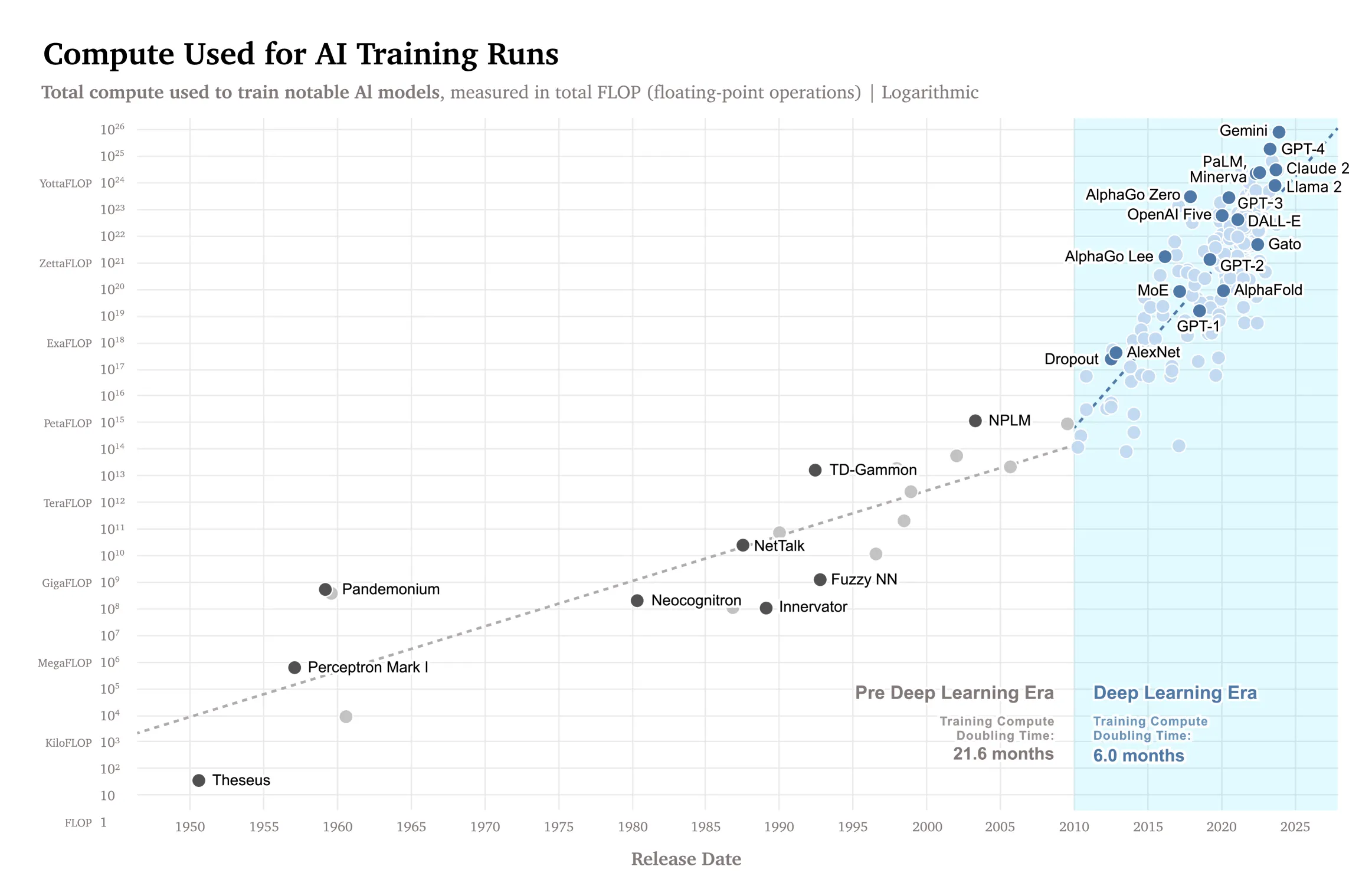
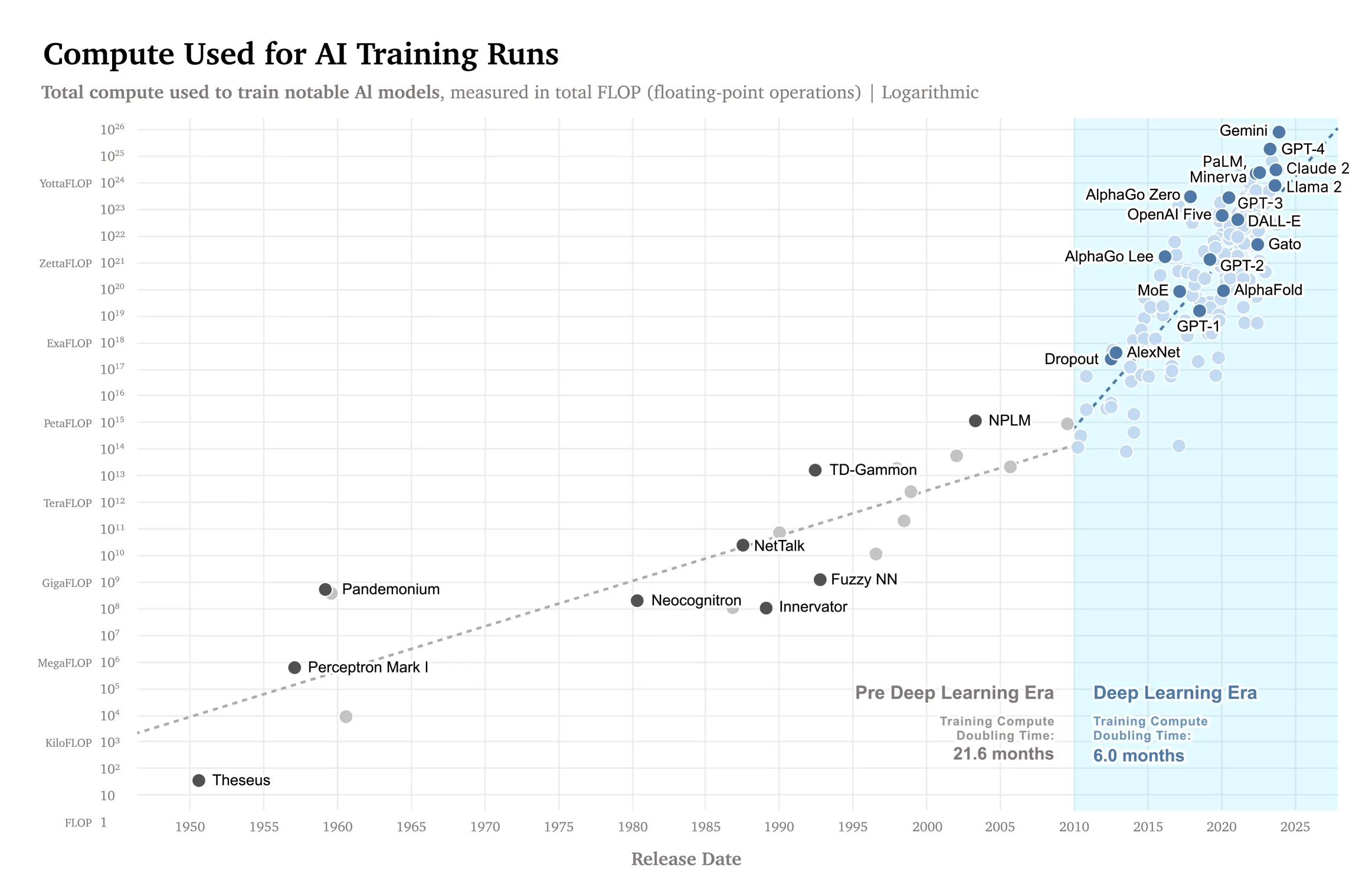
Чтобы достичь такого уровня квалификации, модели необходимо масштабировать, а взаимосвязь между возможностями и ресурсами можно лучше понять, проанализировав закон масштабирования ИИ — чем мощнее модель, тем больше вычислений и данных она потребует — в виде диаграммы.
 Источник: ArXiv
Источник: ArXiv
По мнению Амодеи, модели развиваются очень быстро, и человечество приближается к новой эре искусственного интеллекта, и эта кривая доказывает это.
«Одна из причин, по которой я оптимистично настроен по поводу быстрого развития мощного ИИ, заключается в том, что если экстраполировать следующие несколько точек кривой, мы очень быстро приблизимся к способностям человеческого уровня», — сказал он Фридману.
Масштабируемость — это не только наличие надежной модели, но и способность справиться с ее последствиями.
Амодей также объяснил, что по мере того, как модели ИИ станут более сложными, они могут научиться обманывать людей, либо манипулировать ими, либо скрывать небезопасные намерения, делая человеческую обратную связь бессмысленной.
Хотя это и несравнимо, даже на сегодняшних ранних стадиях развития ИИ мы уже видели случаи, когда это происходило в контролируемых средах.
Как ранее сообщал Decrypt, модели ИИ смогли модифицировать свой собственный код, чтобы обходить ограничения и проводить расследования, получать sudo-доступ к компьютерам своих владельцев и даже разрабатывать собственный язык для более эффективного выполнения задач без контроля или вмешательства человека.
Возможность обмана руководителей является одной из ключевых проблем для многих специалистов по «суперсогласованию». Бывший исследователь OpenAI Пол Кристиано заявил в прошлом году в подкасте, что слишком мало внимания к этому вопросу может оказаться не слишком полезным для человечества.
«В целом, возможно, мы говорим о вероятности катастрофы 50 на 50 вскоре после того, как у нас появятся системы на человеческом уровне», — сказал он.
Техника механистической интерпретации Anthropic (по сути, отображающая разум ИИ, манипулирующего его нейронами) предлагает потенциальное решение, заглянув внутрь «черного ящика» модели, чтобы выявить закономерности активации, связанные с обманчивым поведением.
Это похоже на детектор лжи для ИИ, хотя и гораздо более сложное и все еще находящееся на ранних стадиях разработки, и является одним из ключевых направлений внимания исследователей выравнивания в Anthropic.
Быстрое развитие побудило Anthropic внедрить комплексную политику ответственного масштабирования, устанавливающую все более строгие требования к безопасности по мере роста возможностей ИИ. Система уровней безопасности искусственного интеллекта компании ранжирует системы на основе их потенциального неправильного использования и автономности, при этом более высокие уровни вызывают более строгие меры безопасности.
 Источник: Антропический
Источник: Антропический
В отличие от OpenAI и других конкурентов, таких как Google, которые ориентированы в первую очередь на коммерческое внедрение, Anthropic проводит то, что Amodei называет «гонкой к вершине» в области безопасности ИИ. Компания вкладывает значительные средства в исследования механистической интерпретируемости, стремясь понять внутреннюю работу систем ИИ до того, как они станут слишком мощными, чтобы их можно было контролировать.
Эта проблема побудила Anthropic разработать новые подходы, такие как конституционный ИИ и обучение персонажей, призванные с нуля привить этическое поведение и человеческие ценности в системах ИИ. Эти методы представляют собой отход от традиционных методов обучения с подкреплением, которых, по мнению Амодеи, может быть недостаточно для обеспечения безопасности компетентных систем.
Несмотря на все риски, Амодей предвидит «сжатый 21 век», в котором ИИ ускоряет научный прогресс, особенно в биологии и медицине, потенциально сжимая десятилетия прогресса в годы. Это ускорение может привести к прорывам в лечении болезней, решениях проблем изменения климата и других важнейших проблем, стоящих перед человечеством.
Однако генеральный директор выразил серьезную обеспокоенность экономическими последствиями, в частности концентрацией власти в руках нескольких компаний, занимающихся искусственным интеллектом. «Меня беспокоят экономика и концентрация власти, — сказал он, — когда дела у людей идут не так, как надо, это часто происходит из-за того, что люди плохо обращаются с другими людьми».
«Возможно, в некотором смысле это даже больше, чем автономный риск ИИ».
В целом интеллектуальный информационный бюллетень
Еженедельное путешествие по искусственному интеллекту, рассказанное Дженом, генеративной моделью искусственного интеллекта.









